library(tidyverse)Mastering Regular Expressions: Dealing with String Data in R, Part II
R
tidyverse
regex
string
text
Solving R for Data Science (2ed) Exercises
Introduction
Regular expressions (regex) are a powerful tool for working with string data in R. They might seem complex at first, but with some practice, they can become an invaluable part of your data science toolkit. In this blog post, we will tackle the last four exercises from the “R for Data Science” (2nd edition) book on regular expressions. You can find the first part of the exercises here.
Let’s dive into the world of regex and see how we can manipulate and search text data effectively.
Setting Up
First, let’s load the necessary library:
Exercise 4: British and American Spellings
Question: Create 11 regular expressions that match the British or American spellings for each of the following words: airplane/aeroplane, aluminum/aluminium, analog/analogue, ass/arse, center/centre, defense/defence, donut/doughnut, gray/grey, modeling/modelling, skeptic/sceptic, summarize/summarise. Try to make the sorthest possible regex!
Solution:
# airplane/aeroplane
strings <- c("airplane", "aeroplane")
str_view(strings, "a[ei]ro?plane")[1] │ <airplane>
[2] │ <aeroplane># aluminum/aluminium
strings <- c("aluminum", "aluminium")
str_view(strings, "alumini?um")[1] │ <aluminum>
[2] │ <aluminium># analog/analogue
strings <- c("analog", "analogue")
str_view(strings, "analog(ue)?")[1] │ <analog>
[2] │ <analogue># ass/arse
strings <- c("ass", "arse")
str_view(strings, "a[rs]se?")[1] │ <ass>
[2] │ <arse># center/centre
strings <- c("center", "centre")
str_view(strings, "cent(er|re)")[1] │ <center>
[2] │ <centre># defense/defence
strings <- c("defense", "defence")
str_view(strings, "defen[cs]e")[1] │ <defense>
[2] │ <defence># donut/doughnut
strings <- c("donut", "doughnut")
str_view(strings, "do(ugh)?nut")[1] │ <donut>
[2] │ <doughnut># gray/grey
strings <- c("gray", "grey")
str_view(strings, "gr[ae]y")[1] │ <gray>
[2] │ <grey># modeling/modelling
strings <- c("modeling", "modelling")
str_view(strings, "modell?ing")[1] │ <modeling>
[2] │ <modelling># skeptic/sceptic
strings <- c("skeptic", "sceptic")
str_view(strings, "s[ck]eptic")[1] │ <skeptic>
[2] │ <sceptic># summarize/summarise
strings <- c("summarize", "summarise")
str_view(strings, "summari[sz]e")[1] │ <summarize>
[2] │ <summarise>Exercise 5: Switching First and Last Letters
Question: Switch the first and last letters in words. Which of those strings are still words?
Solution:
# Inspect `words`
str_view(words) [1] │ a
[2] │ able
[3] │ about
[4] │ absolute
[5] │ accept
[6] │ account
[7] │ achieve
[8] │ across
[9] │ act
[10] │ active
[11] │ actual
[12] │ add
[13] │ address
[14] │ admit
[15] │ advertise
[16] │ affect
[17] │ afford
[18] │ after
[19] │ afternoon
[20] │ again
... and 960 more# Replace first letter with last letter
words_switch <- str_replace(words, "(^.)(.*)(.$)", "\\3\\2\\1")
# Explore that the change is correct
cbind(words, words_switch) |> head() words words_switch
[1,] "a" "a"
[2,] "able" "ebla"
[3,] "about" "tboua"
[4,] "absolute" "ebsoluta"
[5,] "accept" "tccepa"
[6,] "account" "tccouna" # View words that are the same as their switched counterparts
str_view(words[words == words_switch]) [1] │ a
[2] │ america
[3] │ area
[4] │ dad
[5] │ dead
[6] │ depend
[7] │ educate
[8] │ else
[9] │ encourage
[10] │ engine
[11] │ europe
[12] │ evidence
[13] │ example
[14] │ excuse
[15] │ exercise
[16] │ expense
[17] │ experience
[18] │ eye
[19] │ health
[20] │ high
... and 17 moreExercise 6: Describing Regular Expressions
Question: Describe in words what these regular expressions match (read carefully to see if each entry is a regular expression or a string that defines a regular expression):
^.*$"\\{.+\\}"\d{4}-\d{2}-\d{2}"\\\\{4}"\..\..\..(.)\1\1"(..)\\1"
Solution:
# ^.*$
# Matches any string, including an empty string, from start to end.
strings <- c("hello", "hello world", "")
str_view(strings, "^.*$")[1] │ <hello>
[2] │ <hello world>
[3] │ <># "\\{.+\\}"
# Matches one or more characters enclosed in curly braces {}.
strings <- c("{1}", "{1234}", "{}")
str_view(strings, "\\{.+\\}")[1] │ <{1}>
[2] │ <{1234}># \d{4}-\d{2}-\d{2}
# Matches numbers in the format YYYY-MM-DD.
strings <- c("2023-06-19", "5678-56-56")
str_view(strings, "\\d{4}-\\d{2}-\\d{2}")[1] │ <2023-06-19>
[2] │ <5678-56-56># "\\\\{4}"
# Matches exactly four backslashes.
strings <- c(r"(\\\\)", r"(\\\\\\)", "####")
str_view(strings, "\\\\{4}")[1] │ <\\\\>
[2] │ <\\\\>\\# \..\..\..
# Matches three characters separated by dots, e.g., .a.b.c
strings <- c(".a.b.c", ".1.2.3", ".x.y.z")
str_view(strings, "\\..\\..\\..")[1] │ <.a.b.c>
[2] │ <.1.2.3>
[3] │ <.x.y.z># (.)\1\1
# Matches any character repeated three times in a row.
strings <- c("aaab", "bbbc", "ccc")
str_view(strings, "(.)\\1\\1")[1] │ <aaa>b
[2] │ <bbb>c
[3] │ <ccc># "(..)\\1"
# Matches two characters repeated consecutively.
strings <- c("abab", "1212", "cdcd")
str_view(strings, "(..)\\1")[1] │ <abab>
[2] │ <1212>
[3] │ <cdcd>Exercise 7: Solving Beginner Regexp Crosswords
Question: Solve the beginner regexp crosswords (https://oreil.ly//Db3NF).
Solution:
Here are the solutions to the beginner regex crosswords:
# Check crosswords function
check_crosswords <- function(pattern_row_1, pattern_row_2, pattern_column_1, pattern_column_2, solution){
solution <- matrix(solution, nrow = 2, byrow = TRUE)
correct <- str_detect(str_flatten(solution[1, ]), pattern_row_1) &
str_detect(str_flatten(solution[2, ]), pattern_row_2) &
str_detect(str_flatten(solution[, 1]), pattern_column_1) &
str_detect(str_flatten(solution[, 2]), pattern_column_2)
correct
}Crossword 1
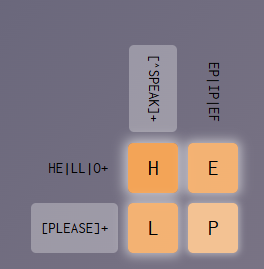
pattern_row_1 <- "HE|LL|O+"
pattern_row_2 <- "[PLEASE]+"
pattern_column_1 <- "[^SPEAK]+"
pattern_column_2 <- "EP|IP|EF"
solution <- c("H", "E", "L", "P")
check_crosswords(pattern_row_1, pattern_row_2, pattern_column_1, pattern_column_2, solution)[1] TRUECrossword 2
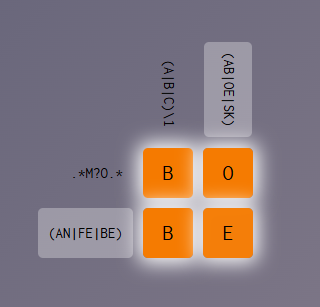
pattern_row_1 <- ".*M?O.*"
pattern_row_2 <- "(AN|FE|BE)"
pattern_column_1 <- "(A|B|C)\\1"
pattern_column_2 <- "(AB|OE|SK)"
solution <- c("B", "O", "B", "E")
check_crosswords(pattern_row_1, pattern_row_2, pattern_column_1, pattern_column_2, solution)[1] TRUECrossword 3
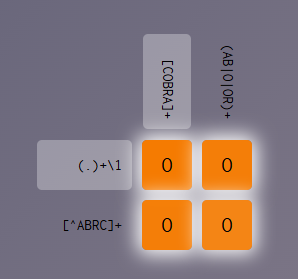
pattern_row_1 <- "(.)+\\1"
pattern_row_2 <- "[^ABRC]+"
pattern_column_1 <- "[COBRA]+"
pattern_column_2 <- "(AB|O|OR)+"
solution <- c("O", "O", "O", "O")
check_crosswords(pattern_row_1, pattern_row_2, pattern_column_1, pattern_column_2, solution)[1] TRUECrossword 4
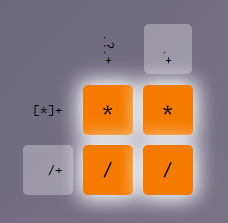
pattern_row_1 <- "[*]+"
pattern_row_2 <- "/+"
pattern_column_1 <- ".?.+"
pattern_column_2 <- ".+"
solution <- c("*", "*", "/", "/")
check_crosswords(pattern_row_1, pattern_row_2, pattern_column_1, pattern_column_2, solution)[1] TRUECrossword 5
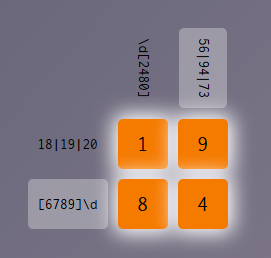
pattern_row_1 <- "18|19|20"
pattern_row_2 <- "[6789]\\d"
pattern_column_1 <- "\\d[2480]"
pattern_column_2 <- "56|94|73"
solution <- c("1", "9", "8", "4")
check_crosswords(pattern_row_1, pattern_row_2, pattern_column_1, pattern_column_2, solution)[1] TRUEConclusion
Regular expressions are a robust tool for string manipulation and text data analysis in R. While they may seem intimidating initially, with practice, they become a powerful asset in your data science toolkit. Through these exercises, we’ve explored various ways to utilize regex to solve complex text processing tasks, from matching patterns in different spellings to switching letters in words and solving regex-based puzzles. Keep practicing and experimenting with regular expressions to unlock their full potential in your data analysis projects.
Happy regexing!
References
Mastering Regular Expressions: Dealing with String Data in R, Part I. EpiStats Blog. https://carlosepistats.github.io/blog/posts/regular_expressions/post.html
R for Data Science (2ed), written by Hadley Wickham, Mine Çetinkaya-Rundel, and Garrett Grolemund. https://r4ds.hadley.nz/
Wickham H, Averick M, Bryan J, Chang W, McGowan LD, François R, Grolemund G, Hayes A, Henry L, Hester J, Kuhn M, Pedersen TL, Miller E, Bache SM, Müller K, Ooms J, Robinson D, Seidel DP, Spinu V, Takahashi K, Vaughan D, Wilke C, Woo K, Yutani H (2019). “Welcome to the tidyverse.” Journal of Open Source Software, 4(43), 1686. doi:10.21105/joss.01686 https://doi.org/10.21105/joss.01686.