Generating Random City Names Based on Syllable Formation Rules
R
strings
functions
creative project
A step-by-step guide on how to generate random city names using syllable-based rules in R.
Author
Carlos Fernández
Published
July 15, 2024
Introduction
In this blog post, we’ll explore how to generate random city names by applying various syllable-based rules to the names of municipalities in the Province of Alicante, Spain. We will be using several functions to transform and manipulate strings in R.
Motivation
This post aims to create fictional names for locations, such as those found in fantasy novels, that resemble Spanish words but do not actually exist. This method can also be applied to generate names for characters or invent unique words for various creative projects. The main challenge is implementing rules for syllable formation, which are the building blocks of word generation, and then finding combinations of syllables present in real words to replicate something similar. By doing so, we can produce names that sound authentic yet are entirely new.
We start by importing the data of municipalities in the Province of Alicante from Wikipedia and cleaning it.
# Import data of municipalities in Alacant Province -------------------------------------------------------------html_alacant <-read_html("https://es.wikipedia.org/wiki/Anexo:Municipios_de_la_provincia_de_Alicante")cities_alicante <- html_alacant |>html_element(".wikitable") |>html_table() |>select(name =`Nombre en castellano`)head(cities_alicante)
# A tibble: 6 × 1
name
<chr>
1 Adsubia
2 Agost
3 Agres
4 Aguas de Busot
5 Albatera
6 Alcalalí
Functions
Pre-process Words
This function transforms the names into a format suitable for syllable extraction. It converts the names to lowercase, replaces spaces and commas, and substitutes specific letter combinations with symbols.
This function applies a regex rule to separate syllables based on predefined patterns. It detects and splits words according to the rule, handling cases where the rule does not apply.
This function repeatedly applies the given regex rule until no more changes occur in the dataset, ensuring all possible syllable separations are handled.
This function reverses the symbol transformations applied by letter_to_symbol, converting symbols back to their original letter combinations.
symbol_to_letter <-function(df, var) { df |>mutate( {{ var }} :=str_replace_all({{ var }}, "_", " "), {{ var }} :=str_replace_all({{ var }}, "ʧ", "ch"), {{ var }} :=str_replace_all({{ var }}, "ʝ", "ll"), {{ var }} :=str_replace_all({{ var }}, "ʀ", "rr"), {{ var }} :=str_replace_all({{ var }}, "q", "qu"), {{ var }} :=str_replace_all({{ var }}, "k([aou])", "c\\1") )}
Spanish Syllable Rules
Here, we define the regex rules for syllable separation. These are based on Spanish rules for syllable separation (inspiration from this document).
These rules are completely dependent on the language we are trying to imitate.
This function applies all the syllable separation rules to the names and converts them back from symbols to letters. It also labels each syllable’s position in the word.
# A tibble: 6 × 3
name silaba posicion
<chr> <chr> <chr>
1 Adsubia ad inicio
2 Adsubia su medio
3 Adsubia bia final
4 Agost a inicio
5 Agost gost final
6 Agres a inicio
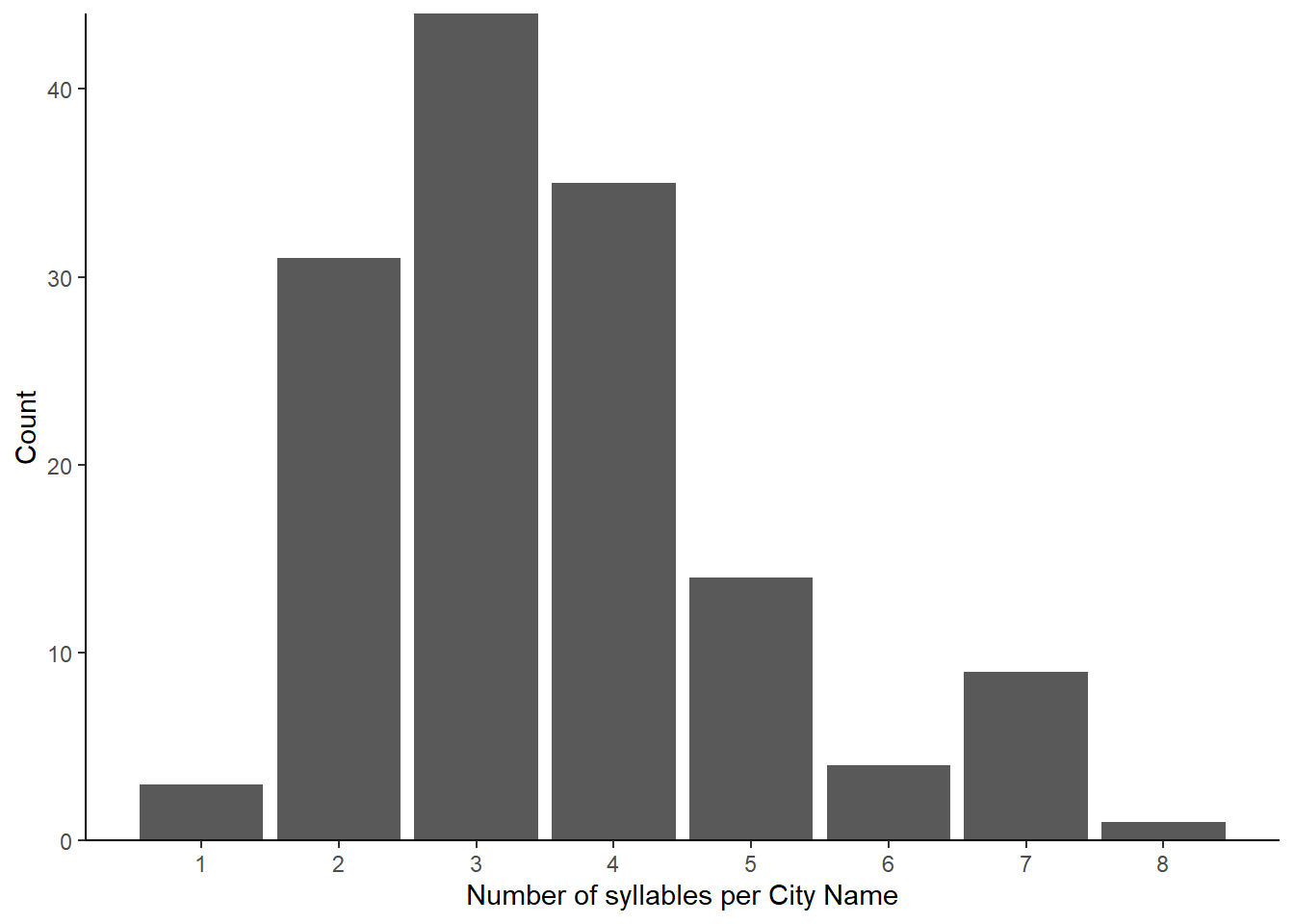
Syllable Frequency
Calculate the frequency of each syllable and its position.
[1] "Semancent" "Pi De Ja" "Ojória"
[4] "Cabalisot" "Ate" "Alniecogost"
[7] "Mondacañedes" "Amataviedro" "San De Las Na"
[10] "Parchenes" "Banar" "Pora"
[13] "Befajuanjachell" "Danipi" "Beniarra De Nas"
[16] "Comarnigo" "Biarrate" "Algra"
[19] "Benichell" "No De Minedanillenes"
Challenges Left
Despite the progress made, several challenges remain. Post-processing errors, such as double blank spaces, multiple accents in a single word, and overly long or difficult-to-pronounce words, need to be addressed. Future improvements could involve using two-syllable combinations instead of single-syllable building blocks, which would create more natural-sounding names at the expense of reduced variety.
Conclusion
In this post, we demonstrated how to generate random city names by applying syllable-based rules to the names of municipalities in Alicante, Spain. By following these steps, you can create your own set of random names for any dataset of city names.