What is, what is it used for, and how to use Lasso regression, with code in R.
Author
Carlos Fernández
Published
February 6, 2024
Introduction
In this post, I explain what Lasso regression is, what it is used for, and how to use it, with code in R.
What is Lasso regression?
Lasso regression is a modified version of linear regression whose objective is to find the simplest model possible. In order to do that, Lasso method penalizes large regression coefficients, leaving smaller coefficients and even removing some variables from the final model (i.e., setting their coefficients to zero).
Lasso is an acronym of Least Absolute Shrinkage and Selector Operator.
What is Lasso regression used for?
Lasso regression is used mainly in two applications:
Model variable selection: Lasso can be used as a method to select the most important variables in a regression model. The least important variables will have their coefficients set to zero, effectively being removed from the final model.
Parameter shrinkage: Lasso’s coefficients are smaller thant those of a simple lineal regression. This helps to avoid overfitting problems.
Given their two main functions, Lasso regression is usually employed in the following situations:
When we have a high-dimensionality dataset, i.e., with a large number of variables.
When we have multicolineallity in our model, i.e., several variables are lineally dependent of one another.
When we want to automatize the model building, via automatizing the selection of the included variables.
How does Lasso regression work?
A traditional multivariable lineal regression model finds a set of regression coefficients (\(\beta_0, \beta_1, \beta_2...\)) that minimizes the residuals’ squared sum (RSS). That is, the distance between the datapoints and the model predictions.
Lasso regression adds another parameter called L1. L1 is defined as the sum of the absolute values of the model coefficients. Lasso method tries to minimize the sum of RSS and L1. As a consequence, Lasso finds a model with smaller regression coefficients. This whole process is known as “L1 regularization”, and it produces a coefficient “shrinkage”.
Every time we run a Lasso regression, whe need to specify the lambda parameter (\(\lambda\)). Lambda represents the relative importance of the L1 parameter compared to the RSS part of the minimization formula.
With \(\lambda = 0\), there is no coefficient shrinkage, and the Lasso model is effectively equal to a regular linear regression model.
As \(\lambda\) grows, there is more shrinkage, and more variables are removed from the model.
If \(\lambda\) were to be infinite, all coefficients would be removed, and we would end up with an empty model.
Lasso regression formula
\(min(RSS + \lambda \sum |\beta_j|)\)
Where
\(RSS\) is the residuals’ square sum.
\(\lambda\) is Lasso’s penalizing factor.
\(\sum |\beta_j|\) is the sum of the absolute values of the regression coefficients.
Code in R
Getting Ready
In this example, we’ll use the glmnet library and the example dataset in mtcars.
Show the code
# install.packages("glmnet") # Install the package (only once)library(glmnet)head(mtcars)
We’ll use mpg (miles per galon) as the outcome variable, and cyl (number of cylinders), hp (horsepower), wt (weight), gear (gear number), and drat (rear axle ratio) as predictive variables.
Show the code
# Define the outcome variabley <- mtcars$mpg# Define the predictive variablesx <-data.matrix(mtcars[, c("cyl", "hp", "wt", "drat", "gear")])
Choose a Value for Lambda
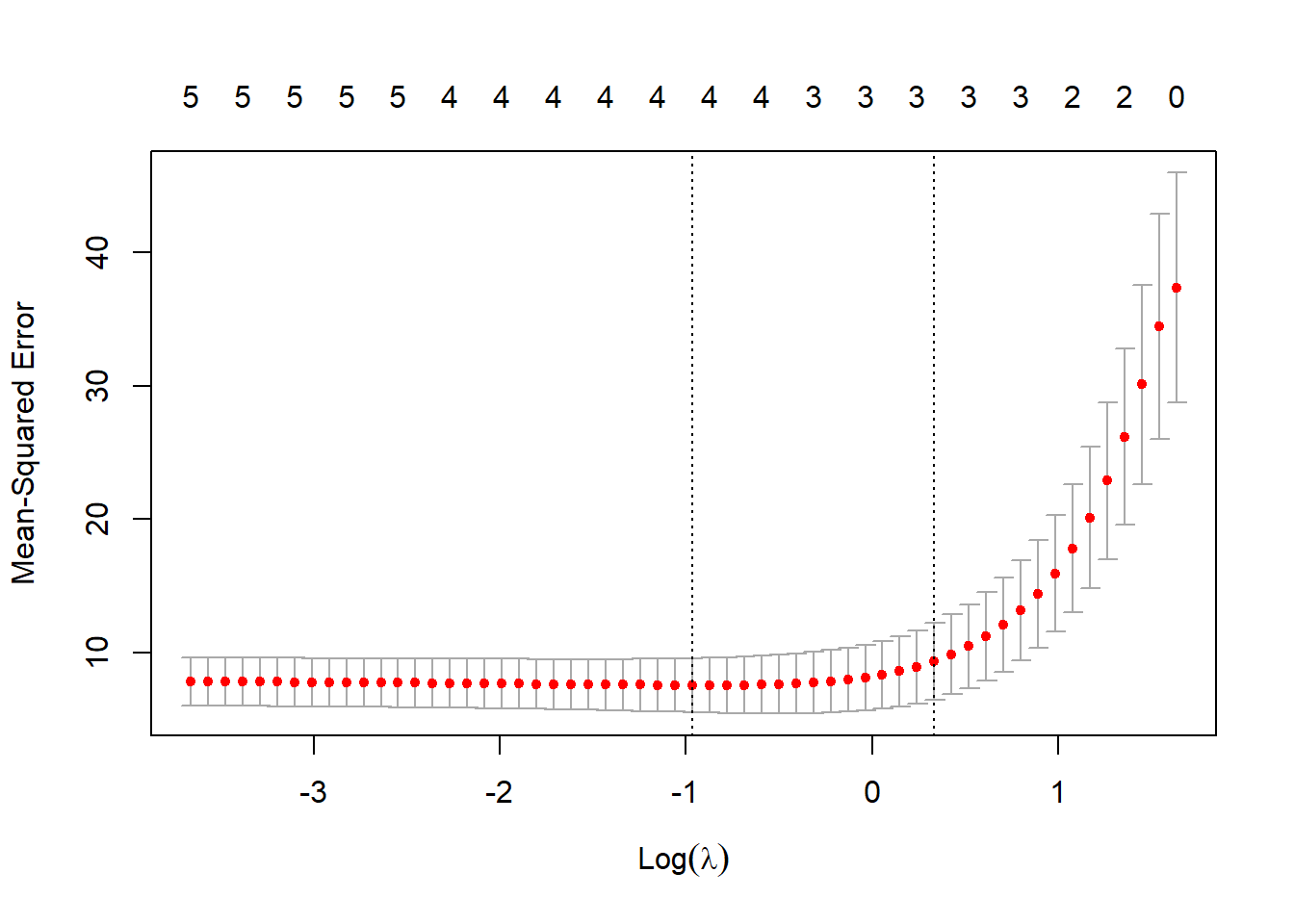
We can choose the value of \(\lambda\) that minimizes the mean-squared error (MSE). The cv.glmnet() function performs “K-fold cross-validation” to identify this \(\lambda\) value.
Show the code
# Cross-validationcv_model <-cv.glmnet(x, y, alpha =1) # Changing the alpha parameter leads to other types of regression# Find the lambda value that minimizes the MSEbest_lambda <- cv_model$lambda.minbest_lambda
[1] 0.3803991
Show the code
# Display the results in a plotplot(cv_model)
The value of lambda that minimizes the MSE turns out to be 0.3803991, which in the plot corresponds to the point \(Log(\lambda)\) = -0.9665344.
Fitting the Model
Show the code
# Model coefficientsbest_model <-glmnet(x, y, alpha =1, lambda = best_lambda)coef(best_model)
6 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 35.99744772
cyl -0.85518839
hp -0.01598015
wt -2.88233444
drat 0.27858106
gear .
We can observe that the coefficient of gear appears as a point, indicating that the Lasso regression has eliminated the coefficient since the variable was not important enough.
Comparison with Linear Regression without Lasso
For comparison, we can see the coefficients that would result from a multiple linear regression model without parameter shrinkage or variable selection.
Show the code
linear_model <-lm(mpg ~ cyl + hp + wt + drat + gear, data = mtcars)model_table <-cbind(coef(best_model), coef(linear_model))colnames(model_table) <-c("Lasso", "Linear")model_table
6 x 2 sparse Matrix of class "dgCMatrix"
Lasso Linear
(Intercept) 35.99744772 33.99417771
cyl -0.85518839 -0.72169272
hp -0.01598015 -0.02227636
wt -2.88233444 -2.92715539
drat 0.27858106 0.73105753
gear . 0.16750690
The coefficients of the Lasso model have been shrunk slightly, especially for the drat variable, and the gear variable has been automatically excluded.
Questions and Curiosities
Some questions arise for further investigation and writing new posts:
How to choose the value of lambda?
How does the method of K-fold cross-validation work?
What sets Lasso apart from other similar models like Ridge?
What is the utility of Lasso regression in the field of public health? What databases can be used as an example?
What articles in the public health field are published using this methodology?